Building with Local Qwen3.6
Built this website twice using Qwen3.6 and GPT5.5. Local models are almost great

I've spent the last couple of weeks playing around with running local models on my RTX3090 24gb. I tried doing a similar thing about an year ago but local models were nowhere near as useful as they are now and I was left pretty disappointed.
Thanks to a bunch of people its been really easy getting started:
- Sudo:
- Club3090: https://github.com/noonghunna/club-3090
But people on twitter post metrics that are engineered to grab your attention, and are not representative of how these models perform on tasks that I'd like to do. Example:
Its cool, but its useless. Also, hermes is a pretty good full-featured harness, but my overwhelmed self likes the simpler Pi.
Here's a weekend experiment I ran.
Setup
How I ran Qwen3.6-27b:
./build/bin/llama-server \
-hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \
-ngl 99 \
-c 131072 \
-np 1 \
-fa on \
-ctk q8_0 \
-ctv turbo3 \
--metrics \
--jinja --chat-template-kwargs '{"enable_thinking": false}'Context length of 128K tokens, flash attention, asymmetric KV cache with key quantization of q8_0 and value quantization set to Turbo3 (thanks to Tom Turney). Also I turned thinking off. I've noticed that Qwen models seem to overthink and get stuck in loops. It also fills the context window that pushes these models to the "dumb zone" quicker.
I used Matt Pocock's /grill-me skill to get to a shared understanding of the plan for this website. I ran it through Qwen and here's the entire conversation I had with it:
I gave the exact same plan to gpt5.5 and qwen3.6 running via the pi-coding-agent harness. The full conversations are here:
Results
GPT5.5 obviously nailed it first try. And it completed the task the fastest.
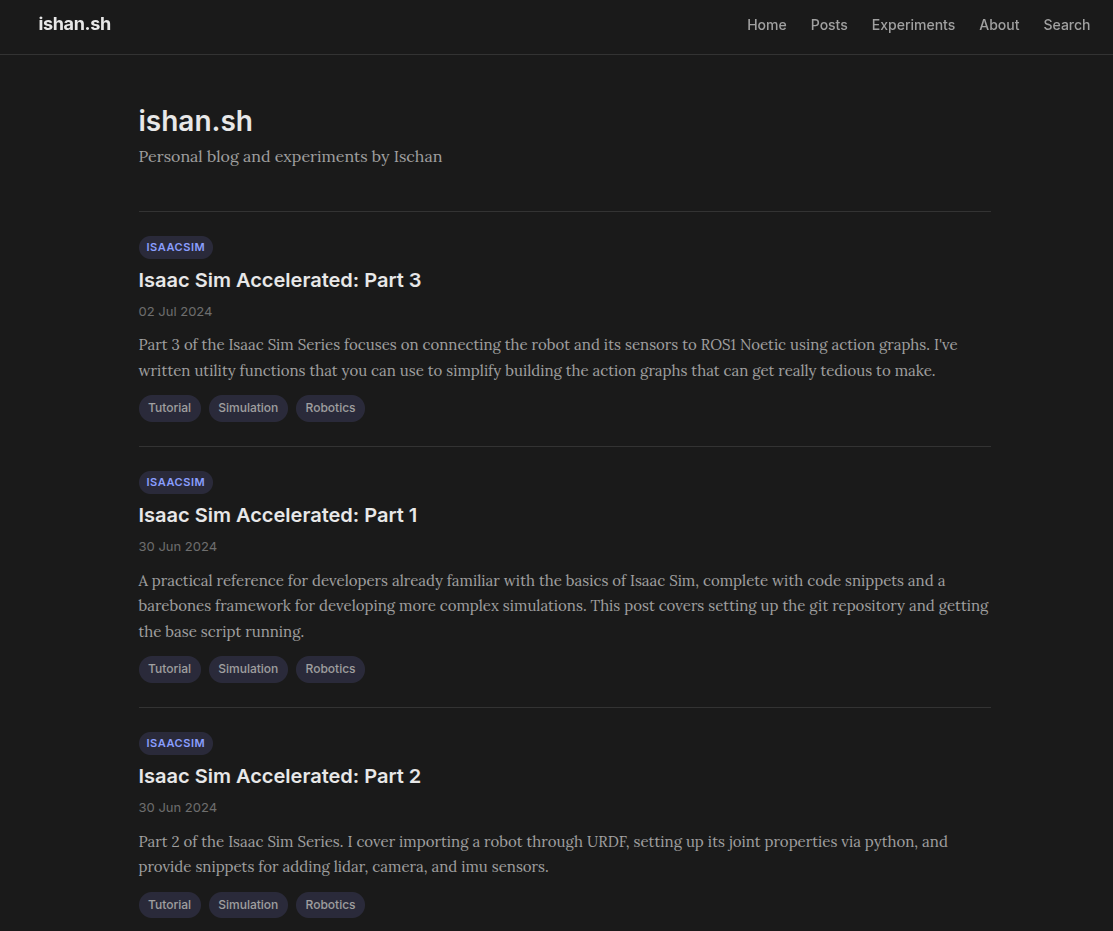
Qwen3.6's implementation was pretty good. It made a lot of mistakes, took way longer to get there, but it got there! It wasn't fun or delightful like I've come to expect from frontier labs, but my PC isn't exactly a frontier lab. It looked like this (notice the spelling mistake "Ischan" in the subheading):
And if you needed any proof that turning thinking off was the right move, here's what Qwen3.6+Thinking built with the exact same prompt and plan:
I (gpt-5.5) built a small tool to track llamacpp's performance. The performance was okay in the beginning but as context increased it slowed way down:
- Run length: 4142s wall (~69 min). 3942s active, 200s idle.
- Output: 46,054 tokens generated, 277,568 prompt tokens processed.
- Decode rate degraded over the run:
- First sample: 28.08 tok/s
- Final sample: 16.19 tok/s (-42%)
- First-half average: 23.44 tok/s
- Second-half average: 17.13 tok/s
- Min: 16.19, Max: 28.09 (across 403 ten-second samples)
As the KV cache fills, decode gets cheaper-per-step but slower-per-token, and the re-prompting (qwen kept re-reading files) of long files makes prompt-eval the dominant cost. By the back half of the run, throughput is below 60% of the cold-start rate. And Qwen made a lot of smaller mistakes. Claude Opus 4.6 (xhigh)'s analysis of the performance and code differences
Conclusion
Using local models reminds me of when I was younger playing GTA-V on my old PC, slightly changing settings to maximize how good the game looked vs having a playable FPS. Using frontier models is like when I got a good enough PC to not care about all that and got on with playing my game.